četrtek, 07. maj 2026 leto 31 / št. 127
Cunami v umetni inteligenci: Kako so kitajska podjetja odplaknila Trumpa in grabežljive ameriške monopoliste
 Vir: Posnetek zaslona, X
Vir: Posnetek zaslona, X
Tehnološki svet je te dni pretreslo več resnih »cunamijev.«
Najprej se je zdelo, da ameriška podjetja prevladujejo na področju umetne inteligence in »klepetalnih robotov«, a nato se je najprej pojavil DeepSeek R1, stranski projekt skupine kitajskih računalniških entuzijastov.
This is what Deepseek was designed to do. It is a gift for the Global Majority. It is a gift to humanity to defend us against the vile Anglo-American Empire. https://t.co/8EjSagpppE pic.twitter.com/SZDEwjPS9a
— Rebecca Chan (@RebeccaYChan) January 30, 2025
Vsi so bili vsi stari pod 35 let, izobraženi na Kitajskem in so na trg poslali odprtokodni sistem, ki so ga »natrenirali« za pičlih 5-6 milijonov dolarjev.
DeepSeek enako dobre ali boljše rezultate ponuja praktično zastonj.
Nato je pod pritiskom domačega tekmeca DeepSeek Alibaba na prvi dan kitajskega novega leta predstavila novo različico svojega klepetalnega robota Qwen 2.5.
Že DeepSeek je dobesedno zrušil ameriške borze in »odpihnil« več sto milijard napihnjene vrednosti ameriških podjetij, ki stojijo za Chat GPT in svojim uporabnikom računajo za svoje storitve od nekaj deset do več sto dolarjev.
After years of banning Chinese scientists and engineers, the U.S. is reversing itself now!
— S.L. Kanthan (@Kanthan2030) January 31, 2025
“Let’s steal their best engineers. We would be better off if the people behind DeepSeek were working here in the US!”
— Atlantic Council at Senate Foreign Relations Committee. pic.twitter.com/iAjB7qLae6
DeepSeek enako dobre ali boljše rezultate ponuja praktično zastonj.
A to ni bilo konec zgodbe.
Kmalu je novo različico svojega modela umetne inteligence izdalo tudi kitajsko tehnološko podjetje Alibaba.

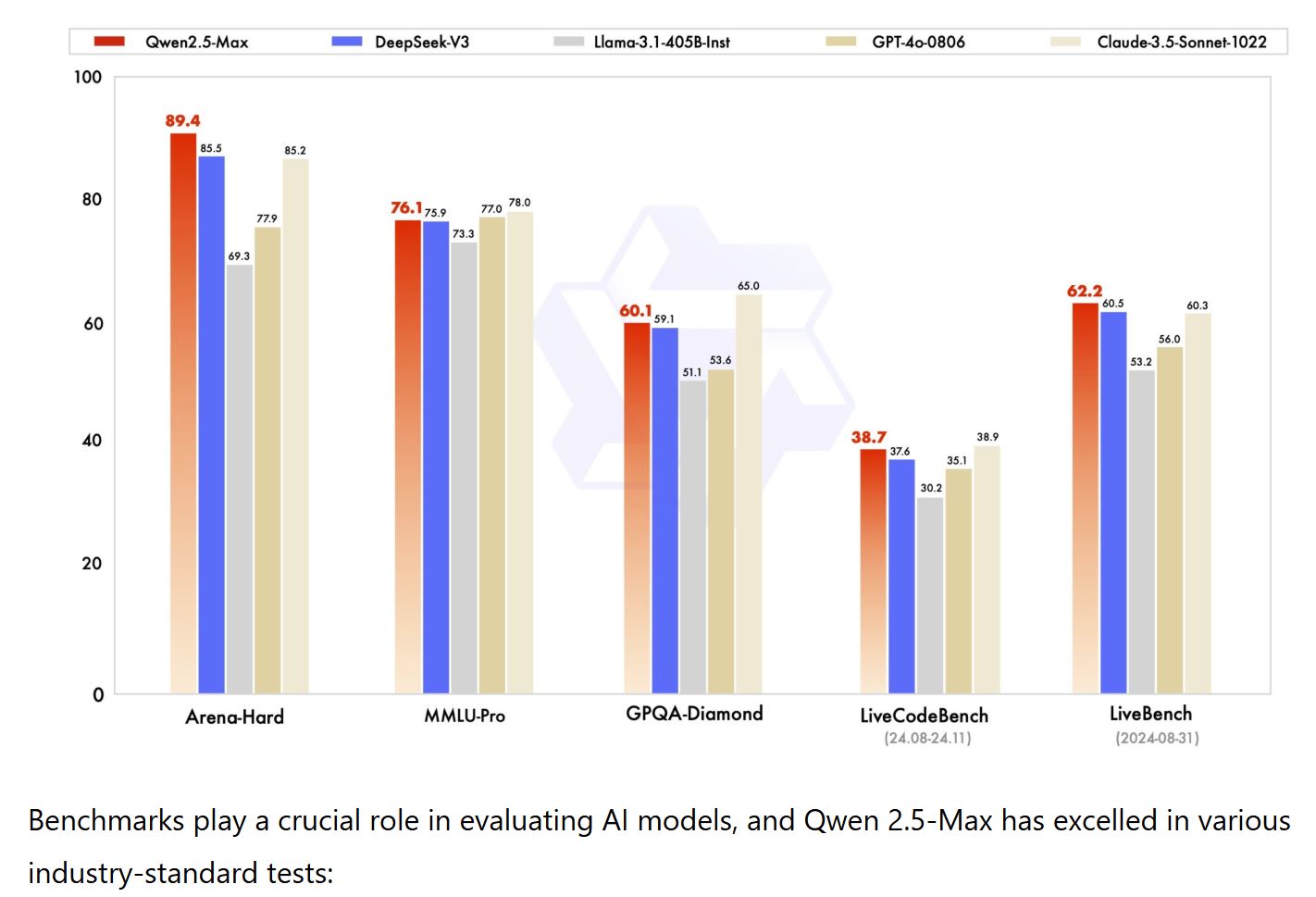
Alibaba za svoj novi model Qwen 2.5 trdi, da presega predhodni DeepSeekov model V3, ki so ga izdali decembra lani.
»Qwen 2.5 prekaša skoraj vse modele GPT-4o, DeepSeek-V3 in Llama-3.1-405B,« so zapisali pri podjetju.
Po besedah njegovega razvijalca to orodje ne samo ustvarja besedilo, ampak ima tudi napredne zmogljivosti kot je analiza dokumentov, tabel, slik in kompleksnih grafov.
BREAKING: a new Chinese model is out.
— Ruben Hassid (@RubenHssd) January 29, 2025
And no. This is NOT DeepSeek.
Meet Qwen-2.5, from the giant Alibaba:
1. It can code, write text, search the web.
2. It can generate images, like Dall-E.
3. It can even generate videos.
Here's everything you need to know: pic.twitter.com/p3WHQArGnY
Poleg tega Qwen 2.5 Max je sposoben obravnavati več jezikov in izvajati poglobljeno analizo vnosov besedila v različnih formatih, vključno z kemijskimi formulami in glasbenimi partiturami.
Na tem področju se najlepše vidi, kako kitajski sistem konkurence deluje, medtem ko poskušajo zahodna podjetja, od Microsofta do Googla, zadržati svoje monopole z uničevanjem konkurence.
Zaradi tega je idealna možnost za raziskovalce, izobraževalne strokovnjake in razvijalce.
Ena od velikih prednosti Qwen 2.5 Max je njegova osredotočenost na multimodalne naloge, omogoča integracijo besedila, slik in drugih formatov v enem samem modelu. To je v nasprotju z orodji, kot je DeepSeek, ki imajo, čeprav so učinkovita, omejitve v nekaterih tehničnih vidikih.
Na primer, Qwen 2.5 Max je bistveno izboljšal prepoznavanje slike, zna razvrščati različne objekte, od spomenikov do vrst rastlin in živali. Prav tako zna analizirati zapletene dokumente, zaradi česar izstopa med drugimi modeli na trgu.
Gre torej za izjemno zmogljiv vizualno-jezikovni model, ki je odprtokoden ter je med drugim sposoben analizirati podatke in vizualni material, prepoznati objekte, interpretirati besedila.
Te funkcije odpirajo nove možnosti v mnogih industrijah.

Na tem področju se najlepše vidi, kako kitajski sistem konkurence deluje, medtem ko poskušajo zahodna podjetja, od Microsofta do Googla, zadržati svoje monopole z uničevanjem konkurence.
Uspeh DeepSeeka je razkril tudi pohlep ameriških tehnoloških podjetij, ki so napovedovala ogromne stroške potrebne za razvoj umetne inteligence – in temu primerno dvigovala cene.
Alibaba je tako pod vplivom konkurence močno oklestil cene svojih modelov, nekaterih celo do 97 odstotkov, kmalu zatem so sledila še druga tehnološka podjetja, na primer Baidu, ki je marca 2023 izdal prvi kitajski ekvivalent ChatGPT, in največ vredno podjetje v državi Tencent.
Je pa med kitajskimi in ameriškimi podjetji seveda velika razlika: kitajska podjetja ne morejo »kupiti vlade« politbiroja in kitajske KPK, kot to počnejo ameriška podjetja doma.
Zato na Kitajskem kapitalizem s socialističnimi značilnostmi deluje, v ZDA pa ne.
Uspeh DeepSeeka je razkril tudi pohlep ameriških tehnoloških podjetij, ki so napovedovala ogromne stroške potrebne za razvoj umetne inteligence – in temu primerno dvigovala cene.
DeepSeek tells the world that artificial intelligence is not American intelligence, and the United States has no right to monopolize the development of AI that belongs to all mankind.
— (@OopsGuess) January 30, 2025
-Dr. Victor Gao pic.twitter.com/ksVULptJNa
Kako se je ameriški sistem »sfižil« na najbolj pomembnem področju za tehnološki preboj v preteklosti, medtem ko je kitajski v celoti uspel, najbolje kaže pot najbolj znanega ameriškega modela in njegovega prvega izzivalca, DeepSeeka.
En velik model umetne inteligence, ChatGPT, je zagotovila neprofitna organizacija OpenAI.
Vendar je njen izvršni direktor Sam Altman kmalu začutil, da bi lahko zaslužil veliko dolarjev.

Leto dni po zaščiti neprofitne strukture OpenAI je Altman učinkovito prevladal nad upravnim odborom in organizacijo spravil v zasebno last.
Altman je za Reuters povedal, da bo podjetje postalo bolj privlačno za vlagatelje, in sicer »z načrtom prestrukturiranja svoje osnovne dejavnosti v profitno korporacijo, ki je ne bo več nadziral njen neprofitni odbor.«
Glavni izvršni direktor Sam Altman je nato prvič prejel tudi lastniški delež v profitnem podjetju, ki bi lahko bilo po prestrukturiranju vredno 150 milijard dolarjev, so ocenjevali analitiki.
DeepSeek is the most powerful AI tool right now.
— Jafar Najafov (@JafarNajafov) January 31, 2025
But 99% of people are using it wrong.
Use these 10 prompts to unlock its full potential: pic.twitter.com/CqA6TBZp7l
Veliki jezikovni model ChatGTP, ki ga je zagotovil OpenAI, je bil zaprtokoden.
Leto dni po zaščiti neprofitne strukture OpenAI je Altman učinkovito prevladal nad upravnim odborom in organizacijo spravil v zasebno last. Veliki jezikovni model ChatGTP, ki ga je zagotovil OpenAI, je bil zaprtokoden.
Bil je črna škatla v oblaku, ki jo je bilo mogoče plačati za klepet ali uporabiti za prevajanje, ustvarjanje vsebine ali analiziranje določenih problemov.
Usposabljanje in vzdrževanje ChatGTP sta zahtevala velike količine računalniške moči in denarja. Bil je nekoliko dražji, vendar v njem ni bilo nobene nove tehnologije.
Algoritmi, ki jih je uporabljal, so bili dobro znani, učni podatki, potrebni za njegovo »programiranje«, pa so bili prosto dostopni na internetu.
Kljub vsemu vznemirjanju glede umetne inteligence to ni bila skrivnost ali celo nova tehnologija. Ovire za vstop v konkurenco so bile nizke.
Toda ZDA so hkrati prepovedale izvoz naprednih čipov na Kitajsko, v upanju, da bodo zavrle njihov razvoj umetne inteligence.
S to politiko se je strinjala tudi Slovenija, ko je v obratni smeri onemogočala, da bi se lahko kitajska tehnologija, predvsem tista podjetja Huawei, prodajala na Slovenskem.

Janševa vlada je s prvo Trumpovo vlado (podpisnik je bil sedanji »demokrat« Anže Logar) podpisala o tem poseben memorandum, Golobova pa je s pregonom kitajskih tehnoloških velikanov nadaljevala.
Politiki so umetno inteligenco dojemali kot naslednjo veliko stvar, ki bo okrepila ameriški nadzor nad svetom.
Poskušali so preprečiti vsakršno morebitno konkurenco, ki bi lahko ogrozila vodilno vlogo, ki so jo ZDA imele na tem področju.
Qwen 2.5 - create a video of Olympic sprinters having a race over water pic.twitter.com/NQcadKi3Bq
— S Will (@segunwilliams) January 30, 2025
Nvidea, zadnji vodilni ameriški proizvajalec čipov, je izgubila milijardo dolarjev, ko so ji prepovedali prodajo najnovejših modelov, specializiranih za umetno inteligenco, na Kitajsko.
Je pa med kitajskimi in ameriškimi podjetji velika razlika: kitajska podjetja ne morejo »kupiti vlade« politbiroja in kitajske KPK, kot to počnejo ameriška podjetja doma. Zato na Kitajskem kapitalizem s socialističnimi značilnostmi deluje, v ZDA pa ne.
Pred dvema dnevoma je Trump napovedal celo Zvezdna vrata, 500 milijard dolarjev vredno naložbo v infrastrukturo umetne inteligence v ZDA.
Trump je naložbo označil za »največji infrastrukturni projekt umetne inteligence v zgodovini«.
Za začetek bodo podjetja v projekt vložila 100 milijard USD, v naslednjih letih pa naj bi v Stargate vložila do 500 milijard USD.
Projekt naj bi ustvaril 100.000 delovnih mest v ZDA, je dejal Trump.
Stargate, DeepSeek und Co.: Wie Deutschland bei KI den Anschluss verpasst https://t.co/eowlVEs3Nf via @derspiegel
— pacino. backlash (@Syzzurp) February 1, 2025
Na isti dan, vendar z veliko manj hrupa, pa je majhno kitajsko podjetje objavilo svoj model umetne inteligence - DeepSeek-R1-Zero in DeepSeek-R1.
Novi modeli DeepSeek imajo boljše referenčne vrednosti kot kateri koli drug model, ki je na voljo.
Za to uporabljajo drugačno kombinacijo tehnik, manj podatkov za usposabljanje in veliko manj računalniške moči. Njihova uporaba je poceni in v nasprotju z OpenAI so resnično odprtokodni.
A to ni vse.
Kitajski modeli so dosegli več z – manj.
Reuters poroča, da je bilo za razvoj DeepSeek-a uporabljenih 2.000 grafičnih procesorjev Nvidia H800, proračun za usposabljanje pa je znašal le 6 milijonov dolarjev.
DeepSeek Principal Researcher: Luo Fuli.
— Jen Zhu (@jenzhuscott) February 1, 2025
Grew up poor in the countryside of Sichuan. Went to Beijing Normal University (not a top tier) to study EE, changed to CS (as “a bad student” she claims).
Post-graduate at Peking U & thought she’d be a product manager at one point … pic.twitter.com/Q5kVW3II9a
Boljših procesorjev namreč kitajskemu podjetju zaradi ameriških izvoznih omejitev ni bilo mogoče kupiti.
Sklep: DeepSeek je torej z 2000 slabšimi procesorji premagal Chat GPT s 25.000 in Groka s 100.000 boljšimi procesorji.
Medtem naj bi OpenAI za usposabljanje ChatGPT 4 uporabil 25.000 čipov A100 prejšnje generacije podjetja Nvidia.
Težko je neposredno primerjati A100 in H800, vendar se vsekakor zdi, da je DeepSeek z manj grafičnimi procesorji naredil več.
Elon Musk je zapisal, da so svojega AI pomočnika Grok usposobili s »100 tisoč vodno hlajenimi H100 na enem samem omrežju RDMA«, kar naj bi bila »najmočnejša gruča za usposabljanje umetne inteligence na svetu!«
Sklep: DeepSeek je torej z 2000 slabšimi procesorji premagal Chat GPT s 25.000 in Groka s 100.000 boljšimi procesorji.
The AI Game Just Changed
— Alfred Lanning (@alfred_lanning1) January 27, 2025
1/ Just days after the Trump-Altman $500B Stargate bombshell, Silicon Valley is SHOOK.
A Chinese startup you've probably never heard of—DeepSeek—just disrupted EVERYTHING.
Here’s how they’re making tech giants look like dinosaurs... pic.twitter.com/iHz1vGW8Ke
Forbes je ocenil: »Ameriški nadzor izvoza naprednih polprevodnikov je bil namenjen upočasnitvi kitajskega napredka na področju umetne inteligence, vendar je morda nehote spodbudil inovacije. Podjetja, kot je DeepSeek s sedežem v Hangzhou, se niso mogla zanašati samo na najnovejšo strojno opremo, zato so bila prisiljena poiskati ustvarjalne rešitve, da bi naredila več z manj… Ustvarili so model, ki ni le med najzmogljivejšimi na svetu, temveč je v celoti odprtokoden, tako da ga lahko vsakdo na svetu pregleda, spremeni in nadgradi.
Učinkovitost modela DeepSeek-R1 je primerljiva z vrhunskimi modeli razmišljanja OpenAI pri različnih nalogah, vključno z matematiko, kodiranjem in kompleksnim razmišljanjem.
Na primer, pri matematičnem merilu AIME 2024 je DeepSeek-R1 dosegel 79,8 odstoka v primerjavi z 79,2 odstoka OpenAI-o1. Pri merilu MATH-500 je DeepSeek-R1 dosegel 97,3 odstoka v primerjavi s 96,4 odstotka OpenAI-o1. Pri nalogah kodiranja je DeepSeek-R1 dosegel 96,3 odstotka pri Codeforces, OpenAI-o1 pa 96,6 odstotka - čeprav je treba opozoriti, da so rezultati primerjalnih testov lahko nepopolni in jih ne smemo pretirano razlagati. Najpomembnejše pa je, da je DeepSeek to uspel doseči predvsem z inovacijami, ne pa z uporabo najnovejših računalniških čipov.«

V časniku Nature so bili prav tako navdušeni: »Kitajski veliki jezikovni model, imenovan DeepSeek-R1, navdušuje znanstvenike kot cenovno dostopen in odprt tekmec 'utemeljevalnim' modelom, kot je o1 podjetja OpenAI.«
»To je divje in popolnoma nepričakovano,« je Elvis Saravia, raziskovalec umetne inteligence in soustanovitelj britanskega svetovalnega podjetja DAIR.AI, zapisal na X.
Model, objavljen pod licenco MIT, se lahko prosto ponovno uporablja, vendar ne velja za popolnoma odprtokodnega, saj njegovi podatki za usposabljanje niso na voljo.
For people that don't really understand, I will explain in Layman's terms#DeepSeek has just unlocked the power of $THETA
— Sky Lion (@MotosakaToshisa) January 28, 2025
AI powered by consumer decentralized EDGE network is now a reality and people really have no clue how huge the implications of this are. pic.twitter.com/h0rpHxe18D
»Odprtost podjetja DeepSeek je precej izjemna,« pravi Mario Krenn, vodja laboratorija za umetne znanstvenike na Inštitutu Max Planck za znanost o svetlobi v Erlangenu v Nemčiji.
DeepSeek R1 je eden najbolj neverjetnih in impresivnih prebojev, kar sem jih kdaj videl - in kot odprtokden je velik dar svetu.
Za primerjavo: o1 in drugi modeli, ki jih je izdelal OpenAI v San Franciscu v Kaliforniji, vključno z njegovim najnovejšim projektom o3, so »v bistvu črne škatle«, pravi Krenn.
Tudi dolgoročni internetni vlagatelji so bili navdušeni.
Marc Andreessen je zapisal: »DeepSeek R1 je eden najbolj neverjetnih in impresivnih prebojev, kar sem jih kdaj videl - in kot odprtokden je velik dar svetu.«
Is this the best-looking team of nerds you have ever seen?
— S.L. Kanthan (@Kanthan2030) January 29, 2025
DeepSeek - the little company that has shaken the world of AI: pic.twitter.com/h1gHDuzsGZ
V časniku Nature so zapisali: »Družba DeepSeek ni objavila vseh stroškov usposabljanja R1, vendar svojim uporabnikom, ki uporabljajo njen vmesnik, zaračunava približno eno tridesetino stroškov delovanja o1. Podjetje je ustvarilo tudi mini 'destilirane' različice R1, da bi raziskovalcem z omejeno računalniško močjo omogočilo igranje z modelom. To dejansko deluje!«
Programska oprema je brezplačna. To je smrtni udarec za OpenAI.
Brian Roemmele je ob tem dodal: »Prijatelji, mislim, da nam je uspelo! Če so nočni testi potrjeni, imamo OPEN SOURCE DeepSeek R1, ki deluje z 200 žetoni na sekundo na Raspberry Pi, ki ni povezan z internetom. Popolna mejna umetna inteligenca, boljša od 'OpenAI', ki je v celoti v vaši lasti, v vašem žepu, brezplačno za uporabo! Sliko Pi bom dal na voljo takoj po zaključku vseh testov. Prosto jo vstavite v Raspberry Pi in imate AI! To je šele začetek moči, ki se pojavi, ko je model AI resnično odprtokoden. Najnovejša strojna oprema Rasberry Pi začne se pri 50 $. Programska oprema je brezplačna. To je smrtni udarec za OpenAI.«
Arnaud Bertrand je pojasnil: »Večina ljudi se verjetno ne zaveda, kako slaba novica je kitajski DeepSeek za OpenAI. Prišli so z modelom, ki na različnih primerjalnih testih ustreza in celo presega najnovejši model o1 podjetja OpenAI, zaračunavajo pa le 3 % cene. V bistvu je to tako, kot če bi nekdo izdal mobilni telefon na ravni iPhona, vendar bi ga prodajal za 30 dolarjev namesto za 1000 dolarjev. Tako dramatično je to. Nazadnje so ga izdali kot odprtokodno rešitev, zato imate celo možnost - ki je OpenAI ne ponuja -, da sploh ne uporabljate njihovega vmesnika API in sami uporabljate model brezplačno.«
BOOM! The AI biosphere built by the world's biggest richest companies has been hit by an earthquake – thanks to a Chinese nerd whose system works better than theirs with a fraction of the computing power and cost. Now DeepSeek R1 is being shrunk to fit onto your phone. pic.twitter.com/NfVK0cTANj
— Nury Vittachi (@NuryVittachi) January 27, 2025
Tudi zgodovina DeepSeeka je neverjetna.
»Leta 2007 so se trije kitajski inženirji odločili, da bodo z umetno inteligenco zgradili kvantni sklad (finančne špekulacije). Zaposlili so ljudi, ki so bili sveže zaposleni na univerzah. Njihov sklad High-Flyer je bil nekoliko uspešen, vendar je kitajska vlada v zadnjih letih začela zatirati finančni inženiring, kvantno trgovanje in špekulacije. Inženirji so s časom, ki so ga imeli na voljo, in neizkoriščeno računalniško močjo v zaledju začeli izdelovati modele DeepSeek. Stroški so bili minimalni. Medtem ko so OpenAI, Meta in Google za izgradnjo svojih umetnih inteligenc porabili milijarde, so stroški usposabljanja za objavljene modele DeepSeek znašali le od 5 do 6 milijonov dolarjev.«
China Destroyed Silicon Valley.
— George Dourakoglou (@yourgwriter) January 28, 2025
They built an AI model that beats OpenAI, Google, and Meta.
It only cost them $6M (vs OpenAI's $17.9 billion).
Here's how DeepSeek is changing AI & why Sam Altman & the US government are worried: pic.twitter.com/w3DgTfzKZg
Nauk zgodbe je, kot sklene MoA, da »včasih imeti manj pomeni inovirati več.«
DeepSeek namreč dokazuje, da ne potrebuješ:
- milijard sredstev
- stotine doktorjev znanosti
- slavnega rodovnika
- le briljantne mlade glave, pogum, da misliš drugače, in pogum, da nikoli ne obupaš.
I tested Deepseek for 72 hours. This AI is on whole NEW LEVEL. Here’s how to make most of it:
— ChetanPal (@theextrovert0) January 28, 2025
Comment ’Deepseek’ to get the ultimate Deepseek cheatsheet in PDF format.
If you liked this:
* Repost this to help it reach others. pic.twitter.com/5m2NRIZhl5
Druga lekcija je, da briljantnih mladih umov ne smemo zapravljati za optimizacijo finančnih špekulacij, temveč za izdelavo stvari, ki jih lahko uporabimo.
DeepSeek dokazuje, kako je nemogoče uporabljati trgovinske in tehnološke ovire za preprečevanje dostopa do tehnologije konkurentom.
DeepSeek dokazuje, kako je nemogoče uporabljati trgovinske in tehnološke ovire za preprečevanje dostopa do tehnologije konkurentom.
Z ustreznimi sredstvi jih lahko preprosto obidejo z inovacijami.
Tudi milijarde dolarjev, politiki, kot je Trump, in goljufi, kot je Sam Altman, ne morejo uspešno tekmovati z dobro usposobljenimi inženirji.
Kot je zapisal avtor pri Guancha: »V kitajsko-ameriški znanstveni in tehnološki vojni ima Kitajska edinstveno prednost prav zaradi ameriške prepovedi. Lahko rečemo, da je Washington izzval našo (kitajsko) močno voljo do preživetja, skrivnost za preboj pa je čim večje izkoriščanje naših omejenih virov. V zgodovini tovrstna zgodba ni nova, to je, da šibki prevladajo nad močnimi in da se majhni uspešno borijo proti velikim. Ameriška stran bo zašla v dilemo vietnamskega tipa - preveč se bo zanašala na svojo absolutno prednost, zato bo zapravila veliko virov in se izgubila zaradi notranje porabe.«
